技术特点
全景视场模型
眼睛的视觉感受因视场模型的不同而异,全景视场模型中的柱形全景、立方体全景和球形全景会使人产生不同的视觉体验,其中以球形视场最符合人眼的视觉习惯,而其它两类视场模型会带来严重的图像和视觉感受畸变。因此,不同于上海杰图公司的立方体视场模型,本项目采用同美国谷歌(Google)公司类似的球形全景视场,给观察者带来更真实的视觉体验。
-

- 全景视场模型
单一视点中心投影技术
每幅图像都有唯一的拍摄视点,一幅完美的有强烈真实感的全景图像也不例外,也应有其对应的唯一视点。目前,国内国际上比较常见的获取全景图像的手段是通过对多方向图像的拼接和融合实现的,但其获得的全景图像并不完美,存在明显的拼接错位现象,导致观察视点不统一,不满足单一视点中心投影,使得图像中楼房建筑出现了弯曲变形。
本项目中,不直接采用拼接融合的方法,而是采用自行构建的球面映射的理论体系和算法以获得保留透视投影关系的球形图像。此球形图像不会存在拼接错位现象和多视点的问题,即符合单一视点中心投影。如图所示。该项技术是构建全景实景混杂现实系统的核心技术。
-
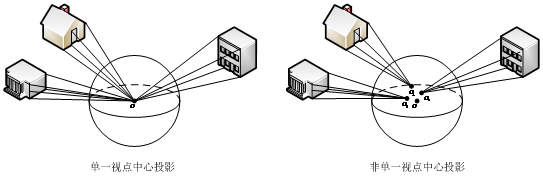
- 单一视点中心投影与非单一视点中心投影示意图(普通方法,例如美国谷歌(Google)公司的方法)(O为单一视点,O1,O2,O3为独立视点)
-

- 美国谷歌(Google)公司全景全景图像非单一视点中心投影
-

- 单一视点中心投影
全景位姿图像技术P3Image
全景位姿图像Panoramic Position and Posture Image,简称为P3 Image。通过从全景实景图像中提取和匹配自然特征点,计算每帧全景实景图像在现实世界中的实际地理位置和实际拍摄姿态,使得每一幅全景图像都具有方位姿态矢量。
-
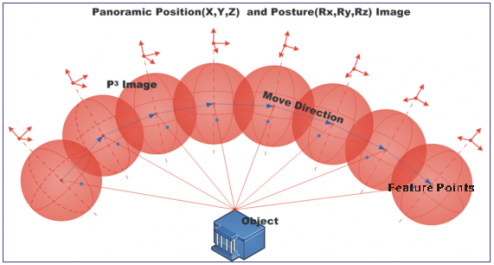
- 全景位姿图像
大规模场景三维建模技术
采用自主研发的移动采集设备,在车辆高速行驶中完成对城市场景三维数据的采集,三维数据经过专门的处理软件,可以建立与实景图像匹配的城市场景三维模型。具体过程如下:
- 通过激光测距仪扫描场景的深度
- 将深度数据与实景图像融合,建立与实景图像匹配的场景三维模型
-
- 激光测距仪
-
- 扫描场景深度
-
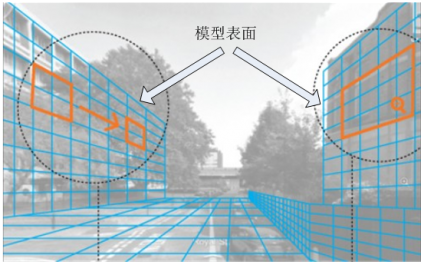
- 建立场景三维模型
经过上述步骤将会得到城市场景数据,如图所示:
-

- 城市场景模型
-

- 全景图像
实景可测量技术
应用计算机视觉理论算法对全景实景图像进行处理分析并获取其深度信息。这时的全景实景图像的每一个像素都具备了深度信息,也就是说这时的全景实景图像中的事物都具备了三维的坐标。因此可以在实景空间进行测量等应用。
-

- 实景测量技术
全景图像信息与地理信息融合技术
本项目将全景位姿图像(P3 Image)的位姿信息与GIS数据库信息进行整合,使全景实景图像数据流与GIS数据地图相连接,形成三维全景实景地理信息平台。如图所示。
-

- 图像信息与地理信息融合技术
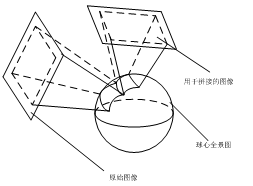
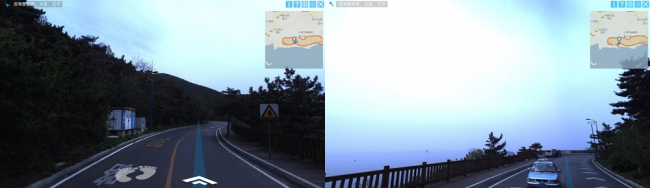
无错位拼接技术
在观察全景图像中的景物时,景物的连续性与场景的平滑过渡影响着人的视觉观察效果。而在通常情况下,多方向的多摄像机系统是全景图像的主要获取途径,需要采用多方向图像拼接和融合技术得到全景图像,因此容易导致拼接错位,定会影响视觉效果。以美国谷歌(Google)公司全景为例,采用此方法获得的全景图像存在明显的拼接错位,如图所示。

-
- 美国谷歌(Google)公司全景图像拼接示意图
与美国谷歌(Google)公司不同,本项目不采用传统的全景图像获取手段,在其提出的球形摄像机模型的基础上,直接通过球面映射的方法获得保留有透视投影关系的球形图像,实现图像的无缝“拼接”,避免了拼接错位现象的出现。如图所示。
-
- 无拼接错位图
-
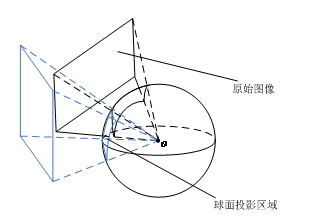
- 球面投影示意图
图像图形深度混杂技术
本项目采用全景位姿图像(结合了位姿信息的图像)技术,在全景实景环境中实现了3D模型(3D人物模型和实体模型)加载显示并与实景环境有机的结合,如人物可以在场景中实现如同在真实环境中的运动,体现了虚拟与现实场景的深度混杂。如图所示。
-

- 图像图形深度混杂技术